【座談会界隈を救いたい】文字起こしを指定のフォーマットに流し込むスクリプト【python-docx + GoogleColab】
あけましておめでとうございます,ばいたるとです。 年末年始は何もしていないのですが,あまりに無為にスマホを眺めているだけなのも気が滅入るので,ブログでも書いて気を紛らわせようと思い立ちました。と思ったらこれやってるだけで朝から晩までかかってしまったので,それはそれでどうしたもんかという気持ち。
ところで皆さま大晦日はどうでしたか? 私はkuraboの家でムサカ1を作ったりYouTuberごっこ2をしたりして遊んでいました。その際にレニが冬コミで仕入れてきた某サークルの会誌を読み,みんなでそのガバガバ出来に胸を打たれていました。特に私は内容よりもディティールを重視するタイプのオタクなので,体裁を整えてやることで救ってあげたい……そう思った次第。それに限らず座談会形式の寄稿をまとめるハードルを下げる一助になれば幸いです。
そもそも何が面倒なのか?
私も漫トロに7年も在籍していますから,会誌作成に際して座談会の文字起こしを何度もやってきました。文字起こしそのものの面倒に加え,座談会のフォーマットを遵守することに相当の労力が割かれることと思います。そもそも目で確認しても直ってんだか直ってないんだか分からんような体裁もあるし。
ところで漫トロピー会誌の座談会企画(総合座談会,個人座談会,糞座談,and so on......)のWord原稿は以下のような体裁が決まっています。

座談会原稿を作成するときは,会員はこの体裁となるフォーマット(通称ふわぺろ)をダウンロードし,コピペして使っています。
とくにややこしいのが本文ですね。話者「内容」を改行を用いずに字下げで実現しており,【話者】と内容を境にフォントが切り替わるため,そのままタイプして文字起こししようとするとフォントがメチャクチャになります。私は最初からWordに作るんじゃなくていったんプレーンテキストに文字起こしをして,フォントが変わらないように本文だけドラッグしてコピペして……としています,面倒くせえ!
記号のルールは地味に曲者です。マガジンマークなどで記号を2つつなげたいときは半角,そうじゃないときは全角,記号の後に文が続く場合は半角スペースを後置する。文字起こし直後の校正では,Word原稿を見てフォントが狂っていないか,半角スペースは適切か,など基本的なチェックに回されることが多いです。本来であれば内容を高めることに時間を費やしたいところで,無駄な労力であると言わざるを得ませんよね。つーか見ても分からんことも多い。
というか,.docxファイルを管理するということそのものがナンセンスだと思います。漫トロでは各会員が担当の文字起こしを.docxファイルで作成し,最終的にコピペで統合して全体の原稿にします。.docxファイルは地味に容量が大きいので会誌作成期間はクラウドの容量がひっ迫しますし,統合の際のコピペも分量が多いのでPCがモッサリしてイライラします。フォーマットが決まっている文章なら.txtなどのプレーンテキストで管理するのが良くないですか?
python-docxによるソリューション
フォーマットとルールが決まった作業をするのであれば,プログラミングの出番でしょう。幸いなことにPythonには.docxファイルを制御できるモジュールが用意されています。
python-docxでは段落(paragraphオブジェクト)ごとに字下げや行間隔を指定し,段落内の文字(runオブジェクト)ごとにフォントや文字サイズを設定できます。話者と内容を.txtファイルなどのプレーンテキストに起こし,それをPythonで読み込む,一行ごとにparagraphを追加し,各paragraphにrunを追加する,runごとにルールを参照し,フォントやスペースを適切に制御する……ということを実現するプログラムを書きます。
GoogleColabによる環境構築
一方でPythonの準備をするのが面倒だという話もあります。ていうかこのスクリプトは2023年の秋会誌作成時に作って広めたんですが,「pythonのパの字も知らなくても,ダブルクリックくらいでできるようにならない?」とかなんとか言われたもんで……。Rを習得するくらいならPython覚えればいいのに。
環境構築の労力はGoogleに押し付けましょう。Googleアカウントを持っているだけでオンライン上でipython notebookを実行できるサービスをふれにあから教えてもらいました。
ちょっとだけ設定が必要ですが,まあコピペすりゃとりあえず動きます。
実装する
GoogleColab側の設定
まず適当なGoogleアカウントにログインした状態でGoogleColabにアクセスすると,左下に「ノートブックを新規作成」と出るので,クリックしてエディタに遷移します。左上からファイル名を変えられるので座談会流し込みスクリプト.ipynbとでもしておきましょう。ctrl+sで保存するとGoogleドライブのColab Notebooksというフォルダに座談会流し込み.ipynbというファイルができているはずです(以下スクリプトと称す)。その場所に座談会流し込みというフォルダを新たに作成し,スクリプトを移動させ,ついでにinputというフォルダを作ってください。

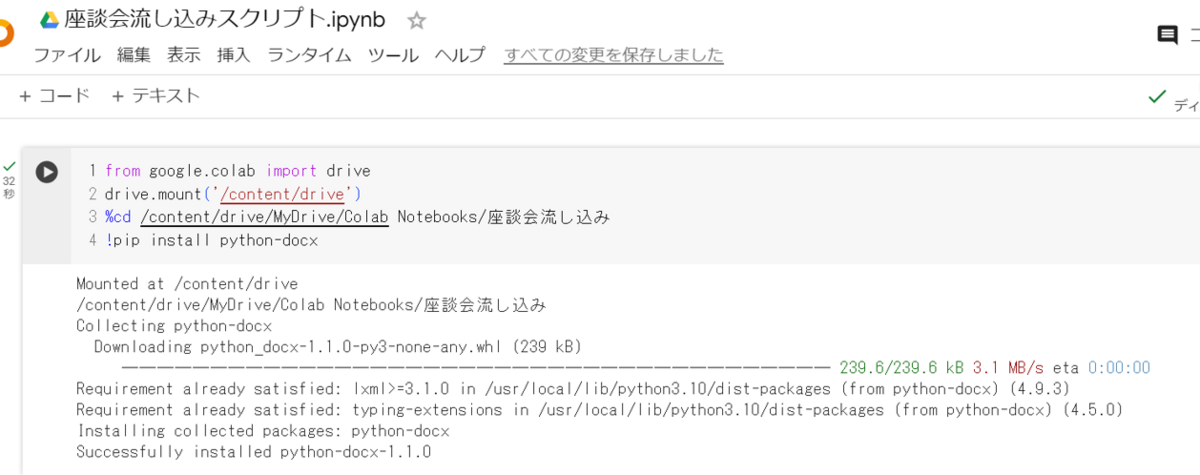
フォルダ構成ができたらスクリプトを開いて以下のコードをセルにコピペし,実行(左側の再生ボタンみたいなのを押す)します。
from google.colab import drive drive.mount('/content/drive') %cd /content/drive/MyDrive/Colab Notebooks/座談会流し込み !pip install python-docx
コードの内容(クリックすると展開されます)
- 1-2行目:Googleドライブ内のファイルに触りたいので,ドライブをマウントする。
- 3行目:カレントディレクトリを先ほど作った「座談会流し込み」フォルダに移動する。ここでエラーが出るなら作ったフォルダ名が間違っている可能性が高い。
- 4行目:GoogleColabにはpython-docxが入っていないので,pip installする。
実行すると
このノートブックに Google ドライブのファイルへのアクセスを許可しますか?
とか出てくるので全部承認してください。こんな感じに結果が出てくると思います。
関数の実装
左上からコードセルを追加して,以下のコードをコピペして実行してください。実行結果は特にありません。
import docx from docx.oxml.ns import qn from docx.shared import Pt from docx.enum.text import WD_ALIGN_PARAGRAPH import os import unicodedata from natsort import natsorted # パラグラフを削除する。 def delete_paragraph(paragraph): p = paragraph._element p.getparent().remove(p) paragraph._p = paragraph._element = None # フォントとサイズを指定して文章を追加する。各パラグラフの最初にはこれを用いる。 def add_font_type_size_run(para,text,font_name,font_size): run = para.add_run(text) run.font.name = font_name run._element.rPr.rFonts.set(qn('w:eastAsia'), run.font.name) run.font.size = Pt(font_size) # パラグラフの字下げや行間を設定する。 def set_hang_space_para(para,hang_length,space_multi): Form = para.paragraph_format Form.first_line_indent = -1*hang_length Form.left_indent = hang_length Form.space_after = Pt(0) Form.line_spacing = space_multi Form.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # 日本語と英数字を区別しながら文章をパラグラフに追加する。強調や半角スペースの処理も含む。 def add_jpn_eng_mixed_run(para,text,Japanese_font,English_font,Emphasize_font,font_size): Flag_full = False # 全角記号のフラグ Flag_half_1 = False # 半角記号のフラグ1 Flag_half_2 = False # 半角記号のフラグ2 Flag_asterisk = False # 強調部分を囲む*記号のフラグ # 1文字ずつ繰り返す。 for _,char in enumerate(text): if Flag_full or (Flag_half_1 and Flag_half_2): # 「!」や「!?」が1つ前に入力されているとき,次の文字が半角スペースではない場合は半角スペースを入れる。 if not char == " ": add_font_type_size_run(para," ",font_name,font_size) Flag_full = False Flag_half_1 = False Flag_half_2 = False if Flag_half_1 == True: # 半角「!?」や「!!」の2つ目の記号を検出したらフラグを立てる。 if char in ("!","?"): Flag_half_2 = True else: Flag_half_1 = False if char in ("!","?") and not Flag_half_1: # 半角「!?」や「!!」の1つ目の記号を検出したらフラグを立てる。 Flag_half_1 = True if char in ("!","?"): # 全角「!」や「?」を検出したらフラグを立てる。 Flag_full = True if char == "*": # 協調部分を囲む「*」を検出したらフラグを入れ替え(強調開始: F->T, 終了: T->F),「*」は入力しない。 Flag_asterisk = not Flag_asterisk continue # unicodedataで文字を判定してフォントを設定する。 ret = unicodedata.east_asian_width(char) if ret == "Na": font_name = English_font else: font_name = Japanese_font if Flag_asterisk == True: # 強調フラグが立っているなら強調フォントを優先。 font_name = Emphasize_font add_font_type_size_run(para,char,font_name,font_size) def main(Merge=False): # フォントファミリーの設定 font = { "Japanese": "MS P明朝", "English": "Century", "Emphasize": "MS Pゴシック", "Title": "MS Pゴシック", "Name": "MS ゴシック" } # 全文字起こしの統合docxを作る(デフォルトでは作らない)。 if Merge: doc_merge = docx.Document("templete.docx") # outputディレクトリが無ければ作成 if not os.path.isdir("output"): os.makedirs("output") # inputディレクトリ内をファイル名の辞書順で繰り返す。 for input in natsorted(os.listdir("input")): input_file = "input/" + input # 流し込み先のテンプレートを読み込む doc = docx.Document("templete.docx") with open(input_file,'r',encoding="utf-8") as f: # 1行目はタイトル,以降の偶数行目はハンドルネーム,奇数行目は本文として処理。 Flag_figure = False # キャプションのフラグ。 for n,line in enumerate(list(f),start=1): if n == 1: # 1行目のみタイトルとして処理。 title = line para = doc.add_paragraph() para.paragraph_format.widow_control = True para.paragraph_format.space_after = Pt(0) para.alignment = WD_ALIGN_PARAGRAPH.CENTER # MS Pゴシック,11 pt,中央揃えでセクションの題目を追加。 add_font_type_size_run(para,title,font["Title"],11) elif n %2 == 0: # ハンドルネームの処理。【】で囲む。 name = line.replace("\n","") font_size = 9 if name == "画像": # ハンドルネーム「画像」を検出するとキャプションとして処理する。 Flag_figure = True font_size = 7 name = "【" + name + "】" # 会話ごとにパラグラフを作成し,ぶら下がり,行間1.2倍を設定。 para = doc.add_paragraph() para.paragraph_format.widow_control = True set_hang_space_para(para,404495,1.2) # MS ゴシック,9 ptでハンドルネームをパラグラフに追加。 add_font_type_size_run(para,name,font["Name"],font_size) elif n %2 == 1: # 本文の処理。 body = line body = body.replace("\n","") # 前行で設定したパラグラフに本文を追加。日本語はMS P明朝,英数字はCentury,強調はMS Pゴシック,9 pt。 if Flag_figure: # キャプションのフラグが立っていると中央揃え,改行追加で本文を追加。 body = body + "\n" para.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER Flag_figure = False add_jpn_eng_mixed_run(para,body,font["Japanese"],font["English"],font["Emphasize"],font_size) # 仕様で冒頭のパラグラフが入るので削除する。 delete_paragraph(doc.paragraphs[0]) # inputファイルごとに変換されたdocxを出力 output_file = "output/" + os.path.splitext(input)[0] +".docx" doc.save(output_file) print(f"'{os.path.splitext(input)[0]}.docx'が'output'に保存されました。") # 統合ファイルを作る場合は各paragraphとrunを格納。 if Merge: for paragraph in doc.paragraphs: paragraph_merge = doc_merge.add_paragraph() # paragraphオブジェクトの様式を強引にコピーする。 Form, Form_merge = paragraph.paragraph_format, paragraph_merge.paragraph_format Form_merge.alignment = Form.alignment Form_merge.first_line_indent = Form.first_line_indent Form_merge.left_indent = Form.left_indent Form_merge.space_after = Form.space_after Form_merge.line_spacing = Form.line_spacing Form_merge.alignment = Form.alignment for run in paragraph.runs: # runオブジェクトの様式を強引にコピーしながら本文を入力。 run_merge = paragraph_merge.add_run(run.text) run_merge.font.size = run.font.size run_merge.font.name = run.font.name run_merge._element.rPr.rFonts.set(qn('w:eastAsia'), run_merge.font.name) # セクションごとに改行がいるので挿入。 doc_merge.add_paragraph().paragraph_format.space_after = Pt(0) # 統合ファイルを出力。 if Merge: # 仕様で冒頭のパラグラフが入るので削除する。 delete_paragraph(doc_merge.paragraphs[0]) doc_merge.save("output/merge.docx") print("'merge.docx'が'output'に保存されました。")
コードの内容(クリックすると展開されます)
- 1-7行目:モジュールの読み込み。
- delete_paragraph:既存の.docxファイルに流し込みをすると仕様で文頭に空のパラグラフが残ってしまうので,それを削除する関数。Stack Overflowのコピペ。
- add_font_type_size_run:パラグラフの最初に文章を追加するのに使う。python-docxで日本語フォントを扱うには呪文を唱える必要があるようで,qiitaを参考に実装した。
- set_hang_space_para:パラグラフの字下げや行間を設定する。特に漫トロのフォーマットのような「ぶら下がり」を設定するには「文頭だけ左側に(マイナス方向)xずらした後に全体を右側に(プラス方向)xずらす」としたらなんかできた。
- add_jpn_eng_mixed_run:フォントを制御しながら本文をパラグラフに追加する。
- 全角「!」「?」を検出するとフラグが立ち,その状態で次の文字が半角スペースじゃなかったら自動で挿入する。
- 半角「!」「?」はそれらが2個続いたことを検出する必要があるのでフラグを2つ用意し,2つのフラグが立った状態に対して同様の処理をする。全角「!?」とか全角スペースはもはや考慮していない。
- アスタリスクで囲まれた強調部分は,アスタリスクを検出する度にフラグを入れ替えることで,強調部分だけフラグを立つように実装した。アスタリスクを検出するとcontinueするのがオシャレポイント。
- unicodedata関数で日本語か英数字かを判別してフォントを決める3。以前は正規表現で判別していて気が狂いそうだった。ただし強調フラグが立っている間は強調フォントで設定を上書きされる。
- main(特に言いたいことだけ):
- font:フォントの設定をまとめた。なんとなく辞書オブジェクトにした。
- for input in natusorted(os.istdir("input")):GoogleColabで実行したら繰り返しが辞書順にならなかったのでnatsordedを入れた。
- for n,line in enumrate(list(f),start=1):別に必要ないけど分かりやすくするためにone-basedにした。
- if n == 1:こいつだけ中央揃え。para.paragraph_format.widow_control = Trueでパラグラフがページを跨がないようにする。para.paragraph_format.space_after = Pt(0)でパラグラフの初めに字下げしないようにする。詳しいことは公式ドキュメントに書いてある。
- elif n %2 == 0:画像フラグはここで立てる。ハンドルネームの略称が【画像】の会員が現れると全てが破綻する。ぶら下げの単位はよく分からないが元のフォーマットは404495らしい。なんかgetterで調べたはずなんだけどもう覚えてない。
- name = name.replace("\n",""):list(f)の中身は改行文字が含まれるので空文字で置換する。
- elif n %2 == 1:画像フラグが立っている場合はキャプションとして処理するため,改行を戻してポイントを下げて中央ぞろえにする。しかし実物なしでキャプション書けるか? という話もある。
- if Merge:デフォルトでは統合ファイルは作らないが,main()の引数にTrueを渡すと統合ファイルも作成する。力技で設定をコピーしているため上手くいかないこともある。
フォントの種類やサイズ,字下げの諸設定を変えずにやると漫トロの座談会原稿になります。使ってない設定もあるので公式ドキュメントでも見ながら好きにいじってください。
入出力ファイルの用意。
入力ファイルは.txtで以下のように行ごとに分けて記述します。余計な改行を入れると全てが崩壊します。また,強調したい部分はアスタリスクで囲っておきます。
- 1行目:セクションのタイトル
- 2, 4, 6, 8, ……行目:ハンドルネーム略称
- 3, 5, 7, 9, ……行目:上のハンドルネームの人の発言
例:6.txtの冒頭
6位『にゅるトロばいたると天国』 パイ ば! い? た!! る!?と??見!て? る!か?……!? はい なにがいいんですか? 読んでないんですけど。 倍足 *これ*readして作って*ない**ranking*は*未完成*です*よ*。 画像 ばいたるとが絶頂しているコマを挿入。生きすぎ1919
1人目の【ぱい】は全角「!」や半角「!?」が入り乱れていますが半角スペースがあったりなかったりします,気が狂う。2人目の【はい】はまともに見えますね。3人目の【倍足】は文中に日本語と英語が入り乱れているほか,強調もわけ分からんことになっています。8, 9行目には画像の指示と仮のキャプションが入力されてあります。
入力ファイルは数字で1.txt, 2.txt, 3.txt,……としておくのがベターかと思います。統合ファイルを作る場合はこの順で流し込まれますので。Googleドライブのinputフォルダに入れておいて下さい。
出力ファイルの設定については,python-docx側で無から作ることもできるらしいのですが,面倒なので普段使っているフォーマットの文章を空にしたものをtemplete.docxとして用意してやります。余白や段組みの設定などは元のファイル側から制御します。その際,本当に空のファイルにしていると設定が巧く反映されないようなので,どうせ後から消すので適当に文章を入れておきます。ここに関しては普段使っているフォーマットがあるから大丈夫でしょう。流石にWord分からないは話にならない。templete.docxはスクリプトと同じファイルに置いておいてください。

ちなみにスクリプトに流し込む前に校正は2,3回通って最低限の体裁合わせと内容のチェックは済んでいるイメージ。最近はOneDriveもブラウザ上での.txtファイルの編集に対応しているので校正の反映もオンラインでできます。校正用原稿はNotepad++でpdfにしたものを印刷するのが良いかと,行数と特殊文字が見れるので。印刷したら余白がたくさん出てもったいかもしんないけどね……。

表示→画面端で折り返す。
印刷→Microsoft Print to PDF。
これを見ると,問題なさそうだった【はい】は文末に全角スペース(IDSP)が残ってたんだと分かりますね。こういうのは校正の段階で消してから流し込みしましょう。
実行と結果
実行するにはGoogleColabで新たなコードセルを追加して,以下のコードを入力して実行するだけです。
main(True)
引数に何も渡さないで実行すると統合ファイルを作らないで個別のファイルだけ流し込みします。原稿がそろってない場合はするといいかも。
実行すると'1.docx'が'output'に保存されました。などと表示されます。出力フォルダは自動で作成されるので問題ありあません。出力される.docxファイルは元の.txtファイルと同じファイル名になっています。
出力されたファイルを見てみるとこんな感じ。見やすくするために半角スペースと全角スペースを可視化しています。

ファイルを確認したところ,
- ハンドルネームと本文の日本語,英数字,強調でフォントが分かれている。
- ハンドルネームのところで適切に字下げされている。
- 全角「!」や半角「!?」などには適切に半角スペースが挿入されている。
- 画像とキャプションを入れるべきところのポイント数が調整されている。
などが実現されていました(豆腐は全角スペースなので元のファイルに残ってるのが悪い)。これによって座談会原稿の体裁を整える煩わしい作業から解放されると考えられます。やったね!!
終わりに
これにて座談会原稿の作業の多くを自動化することができました。漫トロ民に分かりやすく言うと「ふわぺろのコピペ作業からもう解放された」ということです,たぶん。実際どんなもんなんですかね。シチョウくんに使わせたら「作業効率が大幅に上がった」と言っていましたが,少しでも楽になったなら老害冥利に尽きます。こんだけ労力減らしてやったんだから締め切りブッチが減るといいですね。
またこんな場末のブログなんて見られないと思うが,評論島の皆さんの座談会原稿の作成に一助になれば幸いです。
なお本稿は引継ぎ文書も兼ねている。漫トロGoogleアカウントが見つからなかったので自分のでやったが,たぶん役に立つと思うので,暇なときに記事の通りに動かしてもらえると嬉しい。俺(?)もふれにあも卒業してしまうが保守はまぁ……シチョウ(と にく)がおるし大丈夫やろ。
メメ太さん聞こえますか? 俺からあなた(達)への鎮魂歌です
")
【12/25】ピッコマのスクショはNG
こんにちは、漫トロの新会長になったメメ太です。明日やろうと思い続けてたら今日になっちゃってました。間に合いはしたので許してください。
先日久し振りに「オトナ帝国」を観ました。ここ数年ジャンクなアニメばっかり観てたのもあって、感動しました。「古き良き日・大人」対「今・子供」というテーマに対して、「昔」を文字通り「今」にする、つまり大人を子供にする設定が面白いですよね。昔に固執する人たちが、今そして未来を望むようになるストーリーと演出も相まって「クレしん」映画の最高傑作だと思います。
思えば僕の漫画を読む起源は「クレしん」でした。小学生のときは、ブックオフの前を通るたびに親にねだってました。失敗・笑い・家族愛が続いていくのが好きで、夢中になって同じ巻を何回も読み返していましたね。今となっては懐かしいです。というわけで、ひまわり「誕生」の話をします。
赤ちゃんが生まれたゾ
ひまわり誕生回では、産気づいたみさえの元へひろしが仕事から駆け付けます。ひろしは出産をビデオカメラに収めたいので、しんのすけに頼みます。しんのすけはビデオを回していたのですが、出産の瞬間に感銘を受けたあまりカメラのことを忘れてしまうのでした。
なんか暖かくていいなってね。

赤ちゃんの名前が決まったゾ
命名もひとつの誕生なので、有名なこの回の話もします。なかなか決まらない赤ちゃんの名前を紙飛行機で決めるエピソードです。これはアニオリなんですけど、「ひまわり」という名前自体は、作者の臼井儀人が視聴者公募の中から選んだらしいです。しんのすけの紙飛行機が最後まで残って、赤ちゃんのところに止まるんですが、それを銀の介(祖父)が「この子が選んだ名前だ」と言うんですね。それで書かれていた名前が「ひまわり」で、命名されるんです。運命てきなものを感じませんか?

アニメのひまわり誕生回では、しんのすけの作った彼岸花の造花を医者が「きれいなひまわり」と言うという伏線が張られていて感心しました。
なんか違うんだよな
やっぱ「島耕作」の話をする。高校時代からの聖典やからね。島耕作にも娘*1がいるんだけど、その誕生については「係長 島耕作」で描かれているので、その話をしようかな。
娘の誕生
妻・玲子が産気づいても、島は仕事中だから出産に立ち合うなんてできないんだよな。

シマコー界には良くない個人主義(ナンノブマイビジネス文化)が根付いているので、自分のことは自分でするらしい。あと、島が病院に駆け付けたとき、病院側のミスで危うく赤ちゃんの取違いが起きるところだったんだけど…。もう話が滅茶苦茶やね。
赤ちゃんの名前
島耕作「奈実! いいだろ? 奈良の奈、果実の実」
というわけで、赤ちゃんの名前は「奈実」に決定! けどまぁ、波乱が起きないわけがなくて。島が区役所に出生届を出したとき、「奈美」って書いちゃうんだよね。それでも「ま、いいか」って感じなんだけどね。

ちなみに玲子が妊娠したとわかった回で、玲子が寿司を食ってたんだけど、それが並で「奈美」への伏線だったという説もある。
そういえばクリスマス
今更ですが、みなさんいかがお過ごしでしょうか? 今日僕は「クレしん」借りにビデオ1に走ったり、シェアハウスでクソアニメ見ながら冷えたアドカを温めたりしてました。うーん。気づいたんだけど、野原ひまわりの誕生日って9月27日らしくて、クリスマスベイビーなんじゃないかなぁ。ひろしとみさえは、クリスマスにひまわりをこさえたのかな。
おわり
*1:Nyaccoは無視する

【12/24】医者にはなりたくないなぁ。(本音)
こんにちは。アドカの存在を完全に忘れておりすっぽかしてしまったはたはたです。この場を借りて、ばいたるとさんはじめ皆さんにお詫び申しあげます。
今回のアドカのテーマは誕生だそうです。誕生というと産婦人科の領域ですね。産婦人科を主題とした漫画として『コウノドリ』があります。この漫画は医者側からも大変評判が良いようで研修医に読ませる病院もあると聞きます。かくいう私も産婦人科の実習でこれを原作としたドラマを見てレポートを書きました。
妊娠というものは順当に問題なく行われるものであると思いがちですが、死産率は2%程度ありますし、流産や出生後に障害を抱える児などを考えると妊娠とはそれほど順調にいくものであるとも言い難いのかなぁという感想を抱きます。そのような順調にいくとは限らない妊娠の中でも、難しい症例や多職種共同、家族関係などにスポットの当たるような妊娠がこのドラマの中では描かれています。多少お涙頂戴の気があるものの、やはり妊娠とそれにかかわる人々のお話というのはドラマ化せずとも感動するものが多いのですから、物語として仕立てている以上大変心に来るものがあります。私がレポートを書いた回では胎児に口蓋口唇裂という先天性の異常があることがわかった妊婦さんとその家族の葛藤と一度目の出産を無脳症で死産した過去を持つ妊婦さんを対比した構造で描いていました。たとえ治る疾患であるとしてもやはり親としては思い悩むのだという点など、様々学ぶ点がありましたが、医者としては産婦人科医と小児科医の視点の差異が描かれている点が面白く感じられました。産婦人科、小児科(特に新生児にかかわる医師)ともに妊娠に携わるわけですが、妊娠の際に産婦人科は基本母体を中心として動き、胎児が生まれたらすぐに新生児科の医師に胎児は渡されます。ここからもわかる通り基本的に産婦人科は母体を見ることが主で小児科は子供を見ることが主となっています。この回ではカンファレンスにおいて、自身の子供が先天性の疾患を患ったとはいえ治る病気であるのに、あまりにも動揺する母親について小児科の若い医師が苦言を呈したことを産婦人科医師が諫めるシーンがあります。同じ医師であっても主として見る対象が違うと考え方にも差が出るのだといえます。 (モーニングコミックス)")
ここまで自身のレポートの焼き直しみたいな内容を綴ってきましたが、『コウノドリ』は医療知識としてもある程度正しいことが描かれているようですので是非読んでみてください。
そういえば私は『K2』が嫌いだという旨を述べたことがあります。これは別に医療漫画が嫌いであるということが言いたかったわけではなく、スーパードクターなるあり得ないレベルで素晴らしい能力を持つ医師の活躍を主とする漫画が流行ることが、医師に対してこうたれという世間の期待を感じ気に入らんという趣旨でした。『コウノドリ』はスーパードクターとしてではなく一人の人間として医師が描かれており、不満を特に持つことなく楽しむことができました。
 (イブニングコミックス)")
誕生という言葉で思いつく漫画にもう一つ『セントールの悩み』があったのですが、これは一回生の時にアドカで触れていたようなので今年のアドカではお勧めするにとどめておこうと思います。結局今年は実習ばかりの年でした。選んだ漫画も実習関連ですし……。来年は国試勉強だけの年にならないように漫画を読むなりいろいろと能動的にしなければいけないかなぁと考えるばかりです。では皆さんよいお年を。
【特典ペーパー付き】 (RYU COMICS)")
【12/23】俺を育ててくれたボドゲ3選
ふれにあです。
今23時なんですけど、マジで何書けばいいか思いつきません。遅くなります。ごめん。
僕は今年で漫トロ最後なわけで、春から東京で働く予定です(卒業できれば)。あと何か月かすれば引っ越しになるわけですが、そこでこれまで自分が買ってシェアハウスに置いていた「ボードゲーム」の大半を持っていくわけです。
そうすると、今シェアハウスでは盛んに卓が立っているゲームでも廃れていってしまうかもしれません。この記事を残して、遠くの将来に新たなボドゲ伝道師や強プレイヤーが「誕生」してくれればいいなと思い、今回は自分を構成するボードゲーム3選とゲームに対する考え方を書こうと思います。
【ミリオンダウト】
僕がアナログゲームに目覚めたゲームは間違いなくこれだ。ミリオンダウトとは大富豪×ダウトの"天才専用ゲーム"で、1プレイ2~3分の1対1のトランプゲームだ。トランプの中でも14枚のカードしか使わず、しかしそれゆえに僕が知るゲームの中で最も自由度の高い「嘘をつく」ことができる。オンラインではアプリで、オフラインではトランプを使ってプレイできる。


ルールは簡単。1人7枚ずつの手札を配り、それを相手より早くなくすことを目指す。出し方は基本大富豪と同じだが、カードを裏向きにして出すことができる。裏向きのカードは相手が何も言わなければ都合のいいように化け、相手がダウトしたら開いて嘘かを確かめる。嘘だったら山にあるカードを嘘をついた側に押し付けられ、本当だったらダウトした側に押し付けられる。どちらかが手札を先になくしたとき、もう片方の持っている手札の枚数が勝ち点になる。また、ゲーム中に手札が11枚を超えると即座にその枚数分の大負けになってしまう。
このゲームの何が「天才専用」かって、それはなんといっても、真剣にやると信じられないほどイライラすることにある。セオリーは一応あるが嘘つきゲームなので勿論「セオリーは裏をかくためにある」ものであり、プレイヤーは常に理不尽を押し付けて勝ち、理不尽を押し付けられて負ける。負けて負けて負け続ける。1対1のゲームなのに、ほぼレート無差別のオンラインで一番勝っている人(=全盛期の僕)でも1,000試合やって60%しか勝てない*1ってやばくないですか??
ゲームの攻略としては自分の行動のリスクとリターンの比較を徹底することであったり、配られたハンドの最高の結末を現実的な範囲で叶えることであったりと、あらゆるゲームに通じる。それでいてカードを裏向きにすれば何だって作り出すことができ、違和感のないストーリーを作って人を騙したり、違和感を感じて嘘を見破る。「運も実力の内」が本当だということも知ったし、頭では「こんなのほとんど失敗するじゃんよ」と思っていても都合次第ではダウトするような、「デジタル」的思考もここで知った。
まあでも、このゲームには本当に色々な体験をさせてもらった。間違いなく今の自分の思考のベースに関与しているゲームだ。浪人期のセンター試験直前にニコ動で出会ってドハマリし、大学の講義中には講義を聞き、板書を取り、ミリオンダウトを打ち、ミリオンダウトのノートを取るというクアトロタスクをしていた。当時4回生だった同じ学内の先輩*2が同大学内で唯一のプレイヤーだった僕を見つけ、二人で当時僕の家であった熊野寮に集まって何時間もミリオンダウトを打つということをした。本当に懐かしい。このゲームは当時アクティブにプレイしている人≒Twitter上でプレイを公言している人が200人ぐらいで、民度が高いコミュニティだった。1回生の7月に初めてのオフ会として大阪のボードゲームカフェに行って初めて会う人達と知り合い、年上の大学生に「僕ふれにあさんとやるのマジで苦手」と言われて喜んだり、「コヨーテ」のような別のボドゲにも触れた。ミリオンダウトの人と会う回数は結構多く、合計で50人ぐらいのプレイヤーと実際に会って話した。ゲームマーケットに何度も行くようになったのもこのゲームの影響だし、オンオフ問わず何度か大会にも出た。一晩でレートを1950から1480まで落として包丁でリスカしようかと思ったこともあった。このゲームに関する経験は今は書ききれないぐらい多いな。
僕は2019年の4月にこのゲームのアプリ内ランキングでダントツの1位になり、まあそこで満足して熱心にプレイすることはやめてしまったのだけど、27,000試合ぐらいプレイして、何冊ものノートを取った。今でもミリオンダウトのプレイヤーとは多少絡みがあるし、他のボドゲプレイヤーにある程度まとまった時間が取れたときに紹介して遊んでいる。*3今でもアプリはサービス中だが昔ほどの活気がないのは悲しいし、続いていってほしい。
【HANABI】
ミリオンダウトで知り合ったプレイヤーがBGAでこれに興じているのをTwitterで見かけたゲーム。コンポーネントが少ない割に恐ろしいほど硬派で、かつ他のゲームとはかなり異質な、「ちゃんとした」協力ゲームである。今回取り上げるゲームの中ではプレイ回数はかなり少ないのだが、このゲームの「面白さ」は唯一無二だし、個人的には周りの人と最もプレイしたいゲームだ。自分はこのゲームが好きすぎてルール説明のパワポまで作った。
 ボードゲーム")
「ちゃんとしてない」協力ゲームとは全員で目的を共有していても誰か一人が音頭を取って他のプレイヤーをコントロールして、実質的にソリティアになってしまうようなもののことを指すのだが、このゲームはそんなありがちな欠陥を根本的に潰す「情報の非対称性」と「コミュニケーションの制限」が用意されている。2~5人のプレイヤーが一人数枚の手札を持つのだが、そのカードは「自分のものだけ見えない」。それを協力者からの限られた情報に基づいて順番通りに出していき、全員で順番通りにすべてのカードをそろえることを目指す。
このゲームをちゃんと攻略する上で欠かせないのが「フィネス」のようなテクニックだが、これらはこのゲームを数多くプレイしてきた先人によってつくられた"宗教"なので、しばしば同卓者との間に宗教戦争が勃発する。本当に事前に示し合わせてから突き詰めればアクションを符号化して理論上最効率で伝達を済ませる方法*4もあるので、あくまで「お互い初対面だけど頭の中でだったら無限回プレイ経験を積める人」としてのプレイであるというスタンスを示し、噛み合わせていくゲームだ。テクニックが上手くいったり、何とか伝われとイレギュラーな発信をしてそれが意図通りに伝わったときの気持ちよさは他では味わえないものだし、逆に誰か一人がやらかすと途端にすべてが崩壊してしまう恐ろしさもある。前述の宗教を共有していてもなお細かな思想の違いによる争いは絶えず、例えば「このゲームは1回満点を取ることが目的なのか、それとも無限回の平均点を高めることが目的なのか」という議論も絶えない*5し、かつて僕の最初の1手をきっかけにゲームが崩壊し、お互いちゃんとした意志を持っての行動だったので1時間を超えるケンカになったこともある。
また、このゲームはボードゲーム全体で見てもかなり異質かつ学問的であり、Deep Mindがこのゲームの「お互い初対面であるプレイヤーとの対局」をガチで研究している*6。やっていることの延長はまさに「人間とAIのコラボレーション」であり、人類の進歩にもってこいだ。自分は数理情報系の大学院でゲームに関する研究をしているので、一時期本当にこのゲーム関連で修論を書こうかと考えていたことがある。
ということでHANABIは「協力ゲーム」とは仮初の、この世のボードゲームの中でも類を見ないほどのギスギスを生み出す最高のゲームである。最初から争い合ったいた方がまだ和やかだったと言える、極限のシビアさを是非味わってほしい。
【テラフォーミングマーズ】
上二つとは比べものにならないぐらい、長く、重いゲームだ。「火星開拓の一番の功労者となること」を目指して立ち回りを競うというコンセプトで、1プレイで3時間ぐらいかかるのだが、僕は4年で200回ぐらいプレイしている。限られた時間の中で他のプレイヤーがどう動くかを観察・予測し、先手を打ったり後手に回ったりして、火星というパイを少しでも自分のものにしようとする。
 ボードゲーム マルチカラー")

自分はいわゆる「重ゲー」に分類されるゲームは苦手寄りで、それはなぜかというと「序盤の1ミスでその後数時間の負けが確定してしまうから」である。「Barrage」や「Gaia Project」はまさにそれであり、特にプレイヤーの中で実力差があると純粋に楽しむハードルがかなり高い。しかしながら、このゲームはそうした重ゲーの中ではかなり逆転の可能性があり、最後まで順位がわからないことが多い。先述の2作は運要素をかなり排しているというストイックさがあるのは評価したいのだが、「テラフォ」は程よく運要素や秘匿情報があり、妨害に特化したカードによってプレイヤーバランスを取ることが比較的容易で、そしてソリティアとしての楽しみもそれなりに大きい。重ゲーとしてのバランスが非常に良いと思う。
また、運要素がそこそこあるからといって、このゲームがぬるいということではない。やはりプレイすればするほど1行動の大事さがわかってくるし、ゲームがいつ終わるのかをゲームの序盤から想定しておくことや、200種類以上あるカードの中からたった1枚のためのケア行動、一度捨てられて除外されたカードが山札の枯渇によって復活する「転生」の考えなど、大規模なゲームだからこそできる長大な思考を巡らせることができるのは、オタク的な楽しみ方としてかなり面白い。
僕がこのゲームをなぜこんな回数プレイできているのかというと、それは2020年に熊野寮で週に何度も僕を呼び出してテラフォに誘ってくれた3人のおかげである。彼らは僕よりしっかりと考えてゲームを解き明かしていき、毎回1時間を超える感想戦をして夜を明かした。初心者の頃は「めちゃくちゃ強いじゃんこれ」と思っていたカードがカスであることに気づいたり、思わずへえーと言ってしまうフロンティア精神のあるプレイを見られて本当に楽しかった。先週、そのうちの2人と久しぶりにテラフォをしたのだが、負けてもこんなに楽しいと思えるゲームはなかなかない。それはゲームのおかげであり、仲間のおかげでもある。
あとこのゲーム、拡張要素が大量に出ていて公式が出しているものはすべて所持しているのだが、結局バニラが圧倒的に面白いのはちょっと残念だ。
【まとめ】
これら3作のゲームは間違いなく自分の勝負観、延いては人生観の基盤に関与しており、かけがえのない出会いだった。こうした気づきや新しい考えを手に入れられたのは仲間がいたことは勿論だが、僕が大学生という暇のある期間に手を出せたからであるというのも大きいだろう。
今年僕がランキング1位にした漫画もそんな、「余白」にしか突っ込めない形無きものを大事にしようという漫画であった。しょうもないことも大事なことも、仲間がいて気楽にできるってのは特権だね。
 (サンデーうぇぶりコミックス)")

四月からは今ぐらいの余白はなくなってしまうけど、こうした出会いや付き合い、そして愛すべきゲームと仲間たちがくれたものは大事にしたい。メリークリスマス。
*1:https://ameblo.jp/phrenia-dia/entry-12453547363.html
*2:その先輩は去年、ミリオンダウトで知り合った女性と結婚された。
*3:ただし極めて過酷なゲームなので、数多くの人間に薦めたがその場でハマっても1か月以上続けた人はいない。
*4:https://github.com/hanabi/hanabi.github.io/blob/main/misc/hat-guessing.md
*5:僕は後者だが同卓者のほとんどは前者。
【12/22】〈パイズリ〉の誕生―山田邦子発明説の問い直しに向けて―
彗星のごとく現れた教授の原石!京都大学所属D1、美少女研究者のレニです!
レニちゃんは~?今日もかわいいー!!

さて、日々美少女を研究している私ですが、先日、美少女コミック研究者の稀見理都先生が、次のようなツイートをしていました!
ただ、明石家さんまが「広めた」と言う話もあり、それなら十分理解できる説かもしれない。また「えっち」を「H」とアルファベットにした説もある。この手の話、作った、広めた、見つけた、という部分が結構曖昧なまま拡散されることが多い。個人的には「山田邦子、パイズリ発明説」も疑っています。
— 稀見理都 (@kimirito) 2023年11月26日
むむっ、なるほど世の中には「山田邦子パイズリ発明説」というものがあるが、それが本当かどうかは疑わしい、とのことでした!自分は「山田邦子パイズリ発明説」自体知らなかったのですが、なんだか興味がわいてきました!ということで今回は、「山田邦子パイズリ発明説」を検討していきたいと思います!
Wikipediaによれば山田邦子は1960年生まれ、1981年芸能界デビューのお笑い芸人だそうです!Wikipediaにも山田邦子は、「パイズリ」という言葉の発明者として記載されています! ということは、1981年以前に「パイズリ」という言葉が使用されているのを確認できれば、「山田邦子パイズリ発明説」を覆すことができるわけですね!
ということで、まずNDL Ngram Viewerを見てみましょう!これは、この世の全てのメディアが検索できる……わけではないですが、国立国会図書館デジタルコレクションの図書・雑誌約230万点、キーワード17億種類を全て検索できます!ひとまずこれで、「パイズリ」をキーワード検索してみましょう!

おっと、山田邦子以前にも、「パイズリ」の使用が確認できます!1970年代にもぼちぼち検索がヒットし、80年代を通じて徐々に、90年代に爆発的に増加しています!これは「山田邦子パイズリ発明説」を覆すことができそうです!
では、実際に使われているところを見に行きましょう!とうっ!

というわけで、やってきました国会図書館関西館!ここで、デジタルコレクションに収蔵されたデータを直接確認することができます!今回はひとまず、1980年代までの「パイズリ」の使用を、全て確認してみました!結果、111記事が存在していました!以下、時代ごとに見ていきましょう!
1960年代~80年代前半:〈パイズリ〉の誕生
今回調べた中で最も古い「パイズリ」の語の使用は1969年、「週刊文春」に掲載された梶山季之の小説『と金紳士』に登場するものです!

この小説は、サラリーマンの主人公が脱サラして風俗店を開く、という内容なのですが、そこで主人公が引き抜いた「テクニックの三人娘」の中に、「パイズリ」の使用が確認できました!
一人目!同時に三人の男を絶頂させた伝説の持ち主、“スリーP”の辰子!
二人目!パイといっても、麻雀牌や、アップルパイではない!“パイズリ”の陽子!
三人目!自分でエロテープを吹き込み客に聞かせる、”トーキー“お政!
そうです!この“パイズリ”の陽子こそが、国会図書館デジタルコレクションで確認できた、最初の“パイズリ”の使用者です!
小説の中では、「どんなフニャフニャ息子も、この彼女の乳房と乳房に挟みつけられて、ひとしごきされると、アレヨ、アレヨという間に直立してしまう」「巨大なオッパイを使うから“パイズリ”である」と、詳しくプレイの内容が説明されていました!ここからは、当時「パイズリ」というものがあまり一般的ではなかったことが伺えます!
では、この『と金紳士』こそが真の「パイズリ」の発明者なのかと言うと、それは少し事情が異なると考えます!このことを論じるため、1970年代以降の検索結果を見ていきたいと思います!
1970~1983年には、「パイズリ」が13件ヒットしましたが、これらには2つの、特筆すべき点があります!まず第一に、これら全てが「トルコ風呂」、つまり性風俗関係の記事だったということです!
例えば1972年の雑誌『小説宝石』のコラム「おんなのメカニズム」では、「女の乳房って、大きいからいいとは限らないんだ」という前置きを経て、「いや、一ヵ所歓迎される職種があった。トルコ風呂。あのパイズリっていう特殊サービスにゃボインだけが有効だ」という記述がなされており、「パイズリ」が「トルコ風呂」の「特殊サービス」だとされていました!
また、1974年の『オール読物』の記事「雑学する?」では、「ヒップ洗い、パイズリ、燕返し、泡踊り、ポール締め、アナル攻め、ポールのブラシ洗い、原爆攻め、デゴイチ洗い、棺桶攻め、宇宙遊泳、コンニャク攻め、ブラック・サービス、荒波落し……際限がないやね。性技術の開発に骨身をけずっている最近のトルコ界では、秘技四十八手を集大成し、セットセールをしようと企画している店があるとか」という記述がみられ、「パイズリ」がその他のプレイと並んで「トルコ界」の「性技術の開発」の1つとして挙げられていました!
加えて、1984年の雑誌『宝石』の記事「ハードコア座談会 裏ビデオスタッフのないしょ話」も確認しましょう!この記事は、今回確認した中で初めて「パイズリ」という語が、性風俗の言葉として以外で登場しているのですが、それは次のような会話でした!
「監督 K子ちゃん、それだけバストが大きいと”パイズリ”なんかやらされるだろ」
「聖女 え、パイズリってなに?」
「監督 オッパイにペニスをはさんで、こう動かす……」
ここでは、「裏ビデオ」つまりアダルトビデオの監督と女優が座談会をしているのですが、男性の監督は「パイズリ」という言葉を知っているのに対し、女優は「パイズリ」という言葉を知っていないことが分かります!
以上より一点目として、1980年代前半まで「パイズリ」という言葉は、性風俗業界における独自のサービスを示す言葉として使われていた、と考えられます!
そして第二に、「パイズリ」という言葉によって指示されるプレイ内容が、一意に定まっていなかったということです!
まず1975年の『週刊現代』の記事「最新風俗リサーチトルコ第2弾!家庭でも利用できるトルコ風呂48手絵入り解説!」を見てみましょう!ここでは「S、Wに始まり泡踊り、蜂蜜攻めまで生み出したトルコ風呂は性技術開発のパイオニアともいえる」という前置きに始まり、「パイズリ」も、「「乳房の谷間にお客さんのポールちゃんをはさんでもむ」わけだ」とイラスト付きでされています!こうした紹介のされ方自体が、当時「パイズリ」が性風俗業界に閉じていたものだということを示していますが、そのプレイ自体は現在の我々が想起するものと変わりません!

一方、1983年の『週刊宝石』の記事「トルコ・テクニック実践講座」を見てみましょう!ここでも「パイズリ」が「トルコ・テクニック」として画付きで解説されていますが、そこで示されているのは、「おもに乳首で全身を軽くタッチしていくようにする」という、現在の我々が想起するものとは全く異なるものです!

他にも、1979年の『週刊現代』「初めてトルコ風呂に行く諸兄必修の用語とマナー」では、「パイズリ」:「乳房で客の体を刺激すること。乳首がどんどん固くなる感覚を賞味する」という紹介がなされていたり、1976年の『週刊ポスト』「トルコ前線探訪地図入り本場総まくり①評判の大宮”トライスター・サービス””盆栽遊び”の具合」では、「”パイズリ”なる乳房多用の泡踊り」というフレーズが見られたりします!
このように、当時「パイズリ」という言葉は、「パイで男性器をズリズリする」用法と、「パイで全身をズリズリする」用法の、少なくとも2つが存在していました!
1980年代後半:〈パイズリ〉の繁栄
前節での検討により一応、「山田邦子パイズリ発明説」を覆すことはできたのですが、せっかくなのでその後の展開についても見ていきましょう!
先述したグラフでは1980年代後半に、「パイズリ」という言葉の使用が増えていることがわかります!この点について、「パイズリ」使用件数における、記事の主題を確認しました!結果が以下のグラフです!

ここから、2つのことが指摘できます!
まず第一に、「パイズリ」という語の使用が、1985年に拡大していることです!どういうことでしょうか?実際の用法を見てみましょう!
「98センチのバストでパイズリ」(『週刊現代』1984, 「東西超売れっこトルコ嬢100人の秘儀・熟技くらべ」
「ボヨーンと巨大な94センチのオッパイを駆使した”パイズリ”」(『週刊宝石』1985, 「アフター5:00の恋人たち」)
「Dカップのバストを駆使したパイズリ」(『週刊サンケイ』1985, 「厳選・採点表付き東西最新「ソープランド」のすべて」)
「Dカップ、Eカップのデカパイクンが多く、パイズリもバッチリ」(『小説club』1986,「秘伝!イキなソープ遊び」)
このように1980年代では、「パイズリ」という言葉が、胸の大きさを形容する用語とともに使用される用法が頻出していました!
実はこの傾向は、1970年代は見られなかったものです!70年代当時は「パイズリ」は、「性風俗店の珍しいサービス」という語られ方が中心であり、胸の大きさが焦点化されることはなかったんですね!
この背景に何があるのかは検討の必要がありますが、Wikipedia先生によれば80年代当時、「Dカップ」ブームなるものが起きていたそうです*1!閲覧した記事の中でも、「Dカップ」という文字列はこの頃から頻繁に目にした気がしますし、この頃大きな胸へのフェティッシュな欲望が社会的に構築され、それが「パイズリ」への関心の高まりにつながったのかもしれません!
そして第二に、「パイズリ」という言葉が使用される中心が、性風俗店から、アダルトビデオに移ったということです!私はアダルトビデオの歴史には明るくないですが、Wikipedia先生によれば1980年代中ごろよりアダルトビデオというメディアが一般に認知されていったようです*2!当時の雑誌でも、『週刊宝石』のちょっとエッチな情報欄「アダムズ・アイ」で頻繁にアダルトビデオが取り上げられるようになったり、『週刊ポスト』が「ビデオギャル告白シリーズ」というAV女優のインタビュー記事を載せたりしており、そこで使われた「パイズリ」が、検索にたくさん引っかかっていました!

そして、こうしたアダルトビデオ紹介記事から伺えるのが、「パイズリ」が「珍しいもの」から「お約束」に変わっていったことです!先述の通り1970年代の記事では、「パイズリ」は性風俗産業の珍しいプレイとして語られ、時には詳細な解説も加えられていました!しかし、そうした語られ方は1985年以降あまり見られなくなり、また「パイズリ」に詳細な解説が加えられることや、「パイで全身をズリズリする」という用法の揺れも、見られなくなりました!
それどころか、1980年代後半になると、次のようなフレーズが頻出します!
「Dカップ人気が根強いフーゾクに堂々出現、Eカップ巨乳ギャルのマキ嬢」「もちろん、パイズリが得意」(1987『小説club』「読むGスポット」)
「最後は待ってました。パイズリだ」(1989『週刊ポスト』「DカップかAカップかこれぞAV界日本シリーズ対決?「アンチ巨人」派がいるように「アンチ巨乳」派もこんなにいるんです!」)
「胸の大きい子は必ずパイズリっていうのがあるでしょ?」(1989『週刊現代』「ビデオギャル生録インタビュー」)
こうした、「もちろん」「待ってました」「必ず」というフレーズからは、この頃に性産業において「大きい胸」と「パイズリ」との結びつきが自明のものとなったことがわかります!
1990年代:汎〈パイズリ〉化する社会
最後に、「パイズリ」の使用が爆発的に増加する1990年代を、ざっくり見ていきます!全部は見切れないので、今回は1994年、100件を確認しました!内訳が以下です!

まず、この時期に「パイズリ」使用件数が大量に増えた要因として、グラフでも示した「AV通販」と「テレクラ広告」の存在があります!前者では一般誌にてアダルトビデオがカタログ化された広告記事が繰り返し掲載され、その中で「巨乳」ものが紹介される際に、「パイズリ」という言葉を伴っていました!

また後者ではレディコミ誌にてテレクラの広告が掲載され、様々なシチュエーションが提示される中に、「パイズリ」という言葉が伴っていました!1994年の「パイズリ」大爆発は、こうしたアダルトメディアの拡大によるものでした!

また「その他」で示した、性風俗・アダルトメディア以外での使用も拡大しています!これは主に、一般誌の読者投稿欄、小説、漫画などで使用が見られたものです!先のグラフの「その他」にも見られるように、1980年以前には、これらの中では「パイズリ」という言葉はほとんど登場していませんでしたが、1994年にはこれらの中でも登場していました!
その中で興味深い記事が2点あります!一つは主婦と生活社の漫画雑誌「Comic shan」にて、夫婦の性生活に関する記事の中で、「パイズリ」という言葉が紹介されていました!

もう一つは雑誌『生活教育』の特集「性教育をやりにくいと感じている大人たちへ」の「性の商品化・先生と子どもたち」という論考の中で、子供が親の持っている雑誌から性知識を覚えて困る、ということが語られており、その中で子供が「パイズリ」という言葉の意味を大人に聞いた、という例が示されていました!
このように、いままで性風俗、アダルトビデオに閉ざされていた「パイズリ」という言葉は、1990年代により広くメディアや社会に拡大していったと推測されます!
まとめ
ということで今回は、「山田邦子パイズリ発明説」を検討していきました!いかがでしたか?
本稿の検討からは、①「パイズリ」という言葉は1970年代以前より、性風俗店のサービスの名前として用いられていた、②1980年代の巨乳ブーム、およびアダルトビデオの普及に伴い、「パイズリ」という語義の統一と使用の拡大が生じた、③1990年代におけるアダルト系メディアの拡大に伴い、「パイズリ」という言葉がより広まった、という仮説を立てることができるのではないでしょうか!
もちろん今回の検討は国会図書館デジタルコレクションを参照したため、検討対象が一部の雑誌に限られ、より幅広い検討のためには映像メディアや成人向けメディアなども検討する必要があります!皆さんもぜひ「パイズリ」の誕生について調べてみてください!
『大奥』の話しますね。
Amazon.co.jp: 大奥 (ヤングアニマルコミックス) : よしながふみ: 本
よしながふみ『大奥』は、謎の病により男が絶滅しかけている江戸の世を舞台にしており、そこでは男ではなく女が男名を用いて社会を回し、大奥では女将軍を男衆が囲んでいます。こうした一見歪な、しかし当人たちにとっては当たり前な社会の在り方に疑問を抱き「女はなぜ社会を動かしているのか」を問うのが、8代将軍の吉宗です。

その謎を解くために吉宗は、御右筆頭の村瀬を訪ねます。村瀬は大奥での出来事を「没実録」に記録していました。村瀬は吉宗に言います。「ずーっと待ち続けておりましたのにあなた様が来られるまでだーれも訪ねてはくださらなんだ…」
そして吉宗は「没実録」を手に取ります。そこには三代将軍・家光の時代から約100年余り、男性の減少に伴い社会の、そして将軍家の仕組みが変化していく様が記されていました。「没実録」を読み解いた吉宗は、この現状の打破に取り組みます。
ここで吉宗がやってるのって、「ジェンダー秩序の構築性を検討する歴史社会学」なんだよね。僕もジェンダーを歴史的観点から社会学的にアプローチする研究をやってるので、吉宗が「没実録」を手に取る場面、めちゃめちゃ共感してしまった。社会学者、全員『大奥』好きだと思う。
僕はここで、落合恵美子の『21世紀家族へ』を想起せずにはいられない。落合の問いというのは、「女はどうして主婦なんだろう」ということなんだけど、それを検討するにあたって、次のように言っている。
「わたしも最初は、この問いはものすごく大きな問いだと思い込んで、それこそサルと人間の境目くらいまで立ち戻って考えてみなくてはと思っていた。でも、それが大きな間違いだったんですね。」
「その答えというのは、思いのほか近くに転がっています。思いがけず、目の前に。」
落合はこの後、女性が主婦化したのは産業構造が転換し、農業や自営業を中心都する社会かサラリーマンを中心とする社会になって、「男が外、女が内にいて、子を育てる」という家族の在り方が一般化したからだ、と主張するんだけど、そこでまた1つ、エピソードが挿入される。
「子どもがまだ赤ん坊のころ、乳母車を押して畑の間の道を抜けて、公園までよく散歩に出かけました。別に暇をもてあましていたわけではなく、「赤ちゃんに日光浴させてあげなくちゃ」「外気にふれないと夜泣きするし……」などと思って、忙しくても疲れていても毎日そうして散歩していたわけなんですけど、親しくなった農家のおばさんに、あるときこんなことを言われました。「今の若い人はいいね。遊んでりゃいいんだから」」
高度経済成長期以前、多くの女性は農業や自営業をして働いていた。一方落合世代の多くの女性は、「女は主婦」であり、それが「当たり前」だった。ほんの6~70年前にできた「当たり前」の形が、社会を構築し、それ以前のことを我々は容易に忘れてしまう。
「私が子供の頃、村のはずれに気のふれた一人の老爺がいた/その老爺がいつも言っていたのだ/『昔は男が女と同じくらいたくさんいて世が世なら自分は一城の主だった』と/もちろん誰も信じなかった/その老爺は皆に指をさされ笑われたまま山犬に噛まれて死んだ」
「が、ふと思うことがある/この国は初めからこのような国だったのかと」
さっきの落合のエピソードを読んだとき、僕の頭の中では『大奥』の吉宗のセリフが強烈にフラッシュバックして離れなかった。僕が社会学(あるいは資料調査)に感じてる一番の面白みって、やっぱこういう所なんですよ。我々が「当たり前」に捉えている何かしらは、以前は「当たり前」ではない時代があり、しかしそこから「当たり前」になっていき、いつしか人々はそれ以前のことを忘れてしまう。その忘れられたプロセスを掘り起こしていくのは、単に自分の知らなかったことが知れたというのもあるけどそれ以上に、ダンジョンを探検していくようなワクワク感がある。
最近、修論の時のデータで書いてる論文がなかなか査読通らなくてモヤモヤしてたんだけど、今回した調査下らないけどやっぱ楽しかった。論文にはならんが、誰かあとでWikipediaの「パイズリ」と「山田邦子」の項目を書き換えておいてください。
【12/21】本当に面白い会話をしよう<大人数編>
シチョウです。今年も様々なコンテンツが誕生しました。その中でも特に、今年は「面白いとは」「つまらないとは」を問うコンテンツをよく目にしましたね。
これとか。
 (ヤングマガジンコミックス)")
これとか。
また、近年は配信産業の隆盛により、新たな「面白い」を発掘しようという試みも数多くなされています。
これとか。
これとかですね。
ですが、これらのコンテンツを知っていればいるほど、「面白い」人、というわけではありません。このままだと、漫画やお笑いが好きなだけの人です。インプットをいくらしても、アウトプットができなければ何の意味もありません。ですが、我々は漫画家や芸人のように、自分の「面白い」を漫画やネタで、つまり彼らと同様の形式で表現することはできません。では、我々は自分の面白さをどこで表現すればよいのでしょうか?我々がこうしてアドカで記事を執筆するように、文章などで面白さを表現するのも一つの手でしょう。しかし、文章は読んでもらえなければ面白さを理解してもらえません。理解させる前に、一つハードルがあるわけです。より手っ取り早く、己の「面白い」を表現する場、それは会話でしょう。我々が生活するうえで、他者と会話することは避けられません。不可避な以上、もし「面白い会話」ができれば、それだけで他のどの分野で「面白い」より容易に「面白い」と認められるでしょう。では、面白いコンテンツを浴びるように摂取した我々は、いかにして面白く会話ができるのか?
考察します。
そもそも「面白い会話」とは?
そもそも「会話」とは?
[名](スル)複数の人が互いに話すこと。また、その話。「会話を交わす」「親しそうに会話する」「英会話」(デジタル大辞泉より)
この定義に従って、考察する。会話が成立する必要条件、それは「話し相手が存在し、話すターンが両方に回ってくる」ことである。この条件に基づけば、「自分がすべらない話や小噺を披露する」だけの状態を「面白い会話」とは呼べない。加えて「会話」を考察するにあたって考慮すべき要素といえば、その即興性であろう。例えば漫才やコントの台本の暗記・再現で面白い会話ができる、というわけでもあるまい。では?「面白い会話」のロールモデルとは何だろうか。一つ考えられるのは、「マルコポロリ!」「向上委員会」辺りの、芸人だけで構成される平場バラエティ番組だろう。『水曜日のダウンタウン』のように、企画で面白さが担保される番組とは違い、「マルコポロリ!」「向上委員会」ではそういった企画や括り(「○○SP」的な括りが一応毎回あるが、ほとんど機能していない)は到底番組の軸には成りえず、従って、平場でいかに「会話」が展開されるかが番組の面白さに直結する。これらの番組は純度が高いぶん、「会話」を分解して、「今どういう流れで、何でどう言えばウケるか」を明示的に提示するし、自分が話す際にも大いに参考になる。
ただ、あれだけの速度や純度で会話が成立するのは出演者がバラエティの手練れだからであり、我々が想定する会話の相手はバラエティの手練れではない以上、これをそのまま活用できる場面はそう多くはあるまい。「平場」を展開せず、議論などの際に少し場を和ませるくらいで十分な場合も多々あるだろう。そういった場面で活用できるのは、「クレイジージャーニー」『マツコの知らない世界』辺りの、タレントではない人物を主軸としたバラエティ番組の、VTRの合間のスタジオトークであろう。松本人志やマツコ・デラックスが、ゲストやカメラに向かって気の利いた一言を放ち、一旦オチがついて、次のVTRに進む。初対面の相手やフォーマルな場、本音で会話する合間に笑いを交えたい場面など、使える幅が広いのはむしろこちらの方だろう。ただし、こちらはあくまで相手待ちの手法であり、自分から積極的に会話を展開したい際には頼れまい。
つまり、「会話が面白い」人には、いずれの能力も必要である。以下では、「面白い会話」について、この2種類について独立に考察したい。
本当に面白い会話をしよう<大人数編>
まず、平場バラエティ的能力が活きる場面を考えよう。考察にあたって彼らがバラエティの「手練れ」たる所以を考えたい。彼らは一体何が上手いのか?端的に言えば、「空気を読む能力」が高い。より具体的には、「適切なタイミングを見計らって、あるいは自分から場を展開して、適切なコメントを放り込む能力」が高い。これが活きる場面はどこか?1on1なら、ボールは交互に持てばいい。逆に言えば、大人数でボールを回す場なら、この能力は大いに威力を発揮する。そして、この能力が我々の活動に活きる最大の場面、それは総合座談会だろう。最低限話す内容は持っていくが、それを言い終わったら仕事が終わるわけではない。さらに、持ってきたネタを話すタイミングも見計らう必要がある。ただ、それと同等に、あるいはそれ以上に、ここで問題にしたいのは、いかに円滑に場を繋ぎ、周りが話しやすい状況を作るか。全員が持ってきたことを披露するだけの場は座談会とは言えまい。そういった意味で、面白く会話ができることと、その場を面白い空間にできることは、いわば同値なのだ。以下では、「自分を面白く見せる」だけでなく、「周りも面白く見せる」という観点も入れて、何をすれば、面白い会話にできるのかを、特にテクニカルな側面から考察したい。なお、ここでは主に総合座談会でいかに立ち回るかについて主に想定するが、これからの考察は「大人数で喋る場」に対してなら容易に応用可能にも思う。上手く活用してくだされば。
キャラを付ける
「その場における己のポジションを明確にする」と言い換えてもよいだろう。最も強力な手法。バラエティタレントが場を円滑に進めるのは、彼らがキャラを有しているからだ。キャラを有してさえいれば、キャラ通りのことを言えばウケるし、キャラと逆の行動をしてもそれはそれでウケる。さらに言えば、周りも「○○すぎんだろ…」あるいは「お前本当に○○か?」など、ツッコミを入れやすい。つまり、「キャラを付ける」ことは、自分の話す言葉をその言葉が本来持つ力以上に面白く見せつつ、周囲も面白い空間に巻き込めるという点で、「面白い会話をする」ための非常に有効な手段だと言えよう。「キャラ付け」の制限の緩さもこの手法の魅力の一つ。理想は「普段の言動がそのままキャラになる」ことだが、その場だけのキャラを演じてもよいだろう。それはそれでその場のポジションが明確になり、周囲も処理しやすい。逆にNGキャラを考えたい。いくつか挙げられようが、最大のNGポイントは、「周りがそこから拡げづらい」ことだろう。例えば、同じ言葉を連呼する系などは、周囲も毎回同じような処理をせざるを得なくなり、面白味に欠ける。もちろん、別のキャラを用意して、その上で乗っけるなら別に構わないし、似たニュアンスの別の言葉で言い換えれば、その微妙な意味の違いとかで「面白い」空気を醸成できそうだが。あとは、何らかのモノをゴリ押す行為自体をキャラにする、みたいなのもキツいかな。否定以外の選択肢が取れなくなる上に、否定して場の空気がよくなることってまずないからね。下を否定したらパワハラみたいな構図になるし、逆に上を否定するのって、変な勇気いるしね。僕も初めて1353をいじった時は、実は恐る恐るだったんですよ。
話の起点になる
これに関しては、わざわざ書かなくても皆、無意識のうちに行っていることではあろう。場が膠着したタイミングで、別の切り口の話を始める。せっかく話題を持ってきているわけで、できればそれを最適なタイミングで差し込みたい、というのは皆思ってはいるはずで、「場が膠着」=「最適」というのも、ここで陽に示すことでもあるまい。ここで問題にしたいのは、起点とする話について。後に続く人がいる以上、あまり長い、周囲が介入しづらい話は望ましくないだろう。制限時間が近づいているなら、長話を挿入しても特に問題はないとは思うが。
ボールを持ちすぎない
「話の起点になる」「キャラを付ける」と少し被るが、会話は共同作業。最大多数が面白い会話に参加できることが重要だろう。特に目上の場合、自分でなくても言えそうなことは若手に喋らせて、自分でなければ言えない(例えば、キャラの乗った)ことを言ったほうが良いのだろうなと思う。若手であればあるほど必然的にキャラは薄くなってしまうからね。
関わった人間が損しないように処理する
誰かが変なことや場違いなことを言った際のリカバリーも、こういった場では重要だろう。一つ考えられる処理方法は、「当人を、それを言いそうな狂人キャラに持っていく」ことだろうか。ただ、「狂人」をどう設定するかが難しい。ゴールは「損させない」、つまり「誰も嫌な思いをしないこと」であるが、誰がどう言われれば嫌な思いをするかは結局当人次第なので……。
内輪ネタを入れる
個人的には敬遠していたが、今はどちらかといえば、「面白そうな雰囲気になれば/伝わればいいや」というスタンス。そもそもバラエティも広義ではタレントの内輪ノリであるし、その「内輪」がどこまでの範囲か、の違いでしかない。そもそも我々の周囲は、多かれ少なかれ、「自分たちだけが知っている」、つまり「内輪の中にいる」ことに喜びを覚える人間ばかりである。特に我々は、漫画という「内輪」の中におり、この「内輪」は当該漫画を読むだけで誰でも入門できるので、むしろ積極的に内輪ネタを挿入したほうがいいだろう。やる夫スレ読んだら、元ネタの漫画を遡りたくなるやん?真空ジェシカの漫才も、内輪の最大人数を追求してるから、あんなに面白いわけやん?内輪ネタは、使い道次第では、外側の人間を内輪に引きずり込むことができるのだ。
オチをつける
これまでにでてきた言葉からまとめる。意外と難易度が低いわりに、これをやると話が上手い扱いされがちで、コスパがいい。
こんなところでしょうか。最初は『彼女のエレジー』の派生として、分析の体をとったおふざけ記事にするつもりだったのですが、だんだん「いかに面白い会話をするか分析する」ことに意義を見出し、こんな真面目な記事になりました。現状は思いついたことを書き連ねただけに近いですし、書き溜めずに書いた分、詰め切れていない部分も多いので、そう遠くない将来、いくらか改訂を加えると思います。また会話におけるルールの違いに気付き、少人数と大人数の場合で分けて書く必要に迫られました。たぶん少人数編もそのうち出します。気が向いたらまた読みに来てください(←これは、この記事の改訂版と、少人数編の両方についてです)。