あけましておめでとうございます,ばいたるとです。 年末年始は何もしていないのですが,あまりに無為にスマホを眺めているだけなのも気が滅入るので,ブログでも書いて気を紛らわせようと思い立ちました。と思ったらこれやってるだけで朝から晩までかかってしまったので,それはそれでどうしたもんかという気持ち。
ところで皆さま大晦日はどうでしたか? 私はkuraboの家でムサカ1を作ったりYouTuberごっこ2をしたりして遊んでいました。その際にレニが冬コミで仕入れてきた某サークルの会誌を読み,みんなでそのガバガバ出来に胸を打たれていました。特に私は内容よりもディティールを重視するタイプのオタクなので,体裁を整えてやることで救ってあげたい……そう思った次第。それに限らず座談会形式の寄稿をまとめるハードルを下げる一助になれば幸いです。
そもそも何が面倒なのか?
私も漫トロに7年も在籍していますから,会誌作成に際して座談会の文字起こしを何度もやってきました。文字起こしそのものの面倒に加え,座談会のフォーマットを遵守することに相当の労力が割かれることと思います。そもそも目で確認しても直ってんだか直ってないんだか分からんような体裁もあるし。
ところで漫トロピー会誌の座談会企画(総合座談会,個人座談会,糞座談,and so on......)のWord原稿は以下のような体裁が決まっています。

座談会原稿を作成するときは,会員はこの体裁となるフォーマット(通称ふわぺろ)をダウンロードし,コピペして使っています。
とくにややこしいのが本文ですね。話者「内容」を改行を用いずに字下げで実現しており,【話者】と内容を境にフォントが切り替わるため,そのままタイプして文字起こししようとするとフォントがメチャクチャになります。私は最初からWordに作るんじゃなくていったんプレーンテキストに文字起こしをして,フォントが変わらないように本文だけドラッグしてコピペして……としています,面倒くせえ!
記号のルールは地味に曲者です。マガジンマークなどで記号を2つつなげたいときは半角,そうじゃないときは全角,記号の後に文が続く場合は半角スペースを後置する。文字起こし直後の校正では,Word原稿を見てフォントが狂っていないか,半角スペースは適切か,など基本的なチェックに回されることが多いです。本来であれば内容を高めることに時間を費やしたいところで,無駄な労力であると言わざるを得ませんよね。つーか見ても分からんことも多い。
というか,.docxファイルを管理するということそのものがナンセンスだと思います。漫トロでは各会員が担当の文字起こしを.docxファイルで作成し,最終的にコピペで統合して全体の原稿にします。.docxファイルは地味に容量が大きいので会誌作成期間はクラウドの容量がひっ迫しますし,統合の際のコピペも分量が多いのでPCがモッサリしてイライラします。フォーマットが決まっている文章なら.txtなどのプレーンテキストで管理するのが良くないですか?
python-docxによるソリューション
フォーマットとルールが決まった作業をするのであれば,プログラミングの出番でしょう。幸いなことにPythonには.docxファイルを制御できるモジュールが用意されています。
python-docxでは段落(paragraphオブジェクト)ごとに字下げや行間隔を指定し,段落内の文字(runオブジェクト)ごとにフォントや文字サイズを設定できます。話者と内容を.txtファイルなどのプレーンテキストに起こし,それをPythonで読み込む,一行ごとにparagraphを追加し,各paragraphにrunを追加する,runごとにルールを参照し,フォントやスペースを適切に制御する……ということを実現するプログラムを書きます。
GoogleColabによる環境構築
一方でPythonの準備をするのが面倒だという話もあります。ていうかこのスクリプトは2023年の秋会誌作成時に作って広めたんですが,「pythonのパの字も知らなくても,ダブルクリックくらいでできるようにならない?」とかなんとか言われたもんで……。Rを習得するくらいならPython覚えればいいのに。
環境構築の労力はGoogleに押し付けましょう。Googleアカウントを持っているだけでオンライン上でipython notebookを実行できるサービスをふれにあから教えてもらいました。
ちょっとだけ設定が必要ですが,まあコピペすりゃとりあえず動きます。
実装する
GoogleColab側の設定
まず適当なGoogleアカウントにログインした状態でGoogleColabにアクセスすると,左下に「ノートブックを新規作成」と出るので,クリックしてエディタに遷移します。左上からファイル名を変えられるので座談会流し込みスクリプト.ipynbとでもしておきましょう。ctrl+sで保存するとGoogleドライブのColab Notebooksというフォルダに座談会流し込み.ipynbというファイルができているはずです(以下スクリプトと称す)。その場所に座談会流し込みというフォルダを新たに作成し,スクリプトを移動させ,ついでにinputというフォルダを作ってください。

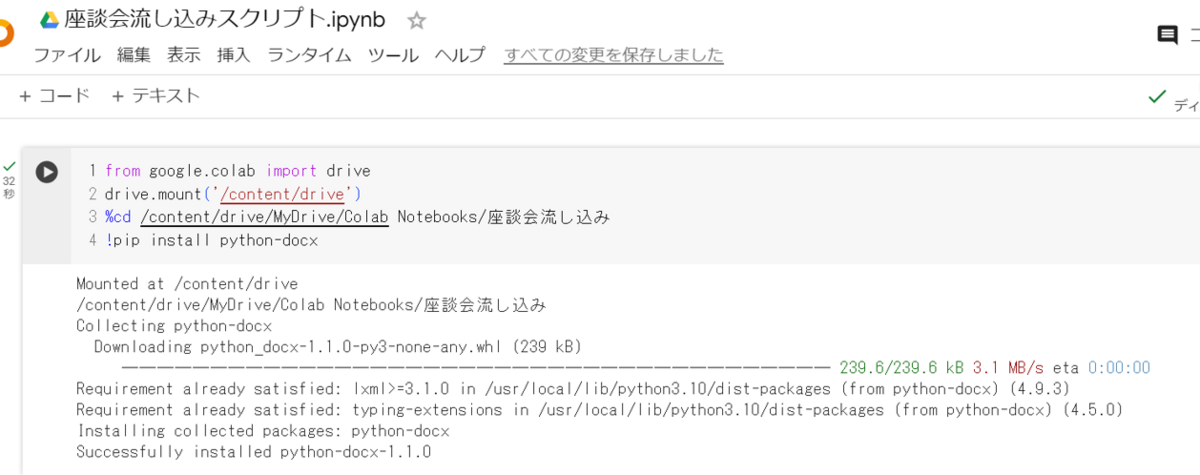
フォルダ構成ができたらスクリプトを開いて以下のコードをセルにコピペし,実行(左側の再生ボタンみたいなのを押す)します。
from google.colab import drive drive.mount('/content/drive') %cd /content/drive/MyDrive/Colab Notebooks/座談会流し込み !pip install python-docx
コードの内容(クリックすると展開されます)
- 1-2行目:Googleドライブ内のファイルに触りたいので,ドライブをマウントする。
- 3行目:カレントディレクトリを先ほど作った「座談会流し込み」フォルダに移動する。ここでエラーが出るなら作ったフォルダ名が間違っている可能性が高い。
- 4行目:GoogleColabにはpython-docxが入っていないので,pip installする。
実行すると
このノートブックに Google ドライブのファイルへのアクセスを許可しますか?
とか出てくるので全部承認してください。こんな感じに結果が出てくると思います。
関数の実装
左上からコードセルを追加して,以下のコードをコピペして実行してください。実行結果は特にありません。
import docx from docx.oxml.ns import qn from docx.shared import Pt from docx.enum.text import WD_ALIGN_PARAGRAPH import os import unicodedata from natsort import natsorted # パラグラフを削除する。 def delete_paragraph(paragraph): p = paragraph._element p.getparent().remove(p) paragraph._p = paragraph._element = None # フォントとサイズを指定して文章を追加する。各パラグラフの最初にはこれを用いる。 def add_font_type_size_run(para,text,font_name,font_size): run = para.add_run(text) run.font.name = font_name run._element.rPr.rFonts.set(qn('w:eastAsia'), run.font.name) run.font.size = Pt(font_size) # パラグラフの字下げや行間を設定する。 def set_hang_space_para(para,hang_length,space_multi): Form = para.paragraph_format Form.first_line_indent = -1*hang_length Form.left_indent = hang_length Form.space_after = Pt(0) Form.line_spacing = space_multi Form.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY # 日本語と英数字を区別しながら文章をパラグラフに追加する。強調や半角スペースの処理も含む。 def add_jpn_eng_mixed_run(para,text,Japanese_font,English_font,Emphasize_font,font_size): Flag_full = False # 全角記号のフラグ Flag_half_1 = False # 半角記号のフラグ1 Flag_half_2 = False # 半角記号のフラグ2 Flag_asterisk = False # 強調部分を囲む*記号のフラグ # 1文字ずつ繰り返す。 for _,char in enumerate(text): if Flag_full or (Flag_half_1 and Flag_half_2): # 「!」や「!?」が1つ前に入力されているとき,次の文字が半角スペースではない場合は半角スペースを入れる。 if not char == " ": add_font_type_size_run(para," ",font_name,font_size) Flag_full = False Flag_half_1 = False Flag_half_2 = False if Flag_half_1 == True: # 半角「!?」や「!!」の2つ目の記号を検出したらフラグを立てる。 if char in ("!","?"): Flag_half_2 = True else: Flag_half_1 = False if char in ("!","?") and not Flag_half_1: # 半角「!?」や「!!」の1つ目の記号を検出したらフラグを立てる。 Flag_half_1 = True if char in ("!","?"): # 全角「!」や「?」を検出したらフラグを立てる。 Flag_full = True if char == "*": # 協調部分を囲む「*」を検出したらフラグを入れ替え(強調開始: F->T, 終了: T->F),「*」は入力しない。 Flag_asterisk = not Flag_asterisk continue # unicodedataで文字を判定してフォントを設定する。 ret = unicodedata.east_asian_width(char) if ret == "Na": font_name = English_font else: font_name = Japanese_font if Flag_asterisk == True: # 強調フラグが立っているなら強調フォントを優先。 font_name = Emphasize_font add_font_type_size_run(para,char,font_name,font_size) def main(Merge=False): # フォントファミリーの設定 font = { "Japanese": "MS P明朝", "English": "Century", "Emphasize": "MS Pゴシック", "Title": "MS Pゴシック", "Name": "MS ゴシック" } # 全文字起こしの統合docxを作る(デフォルトでは作らない)。 if Merge: doc_merge = docx.Document("templete.docx") # outputディレクトリが無ければ作成 if not os.path.isdir("output"): os.makedirs("output") # inputディレクトリ内をファイル名の辞書順で繰り返す。 for input in natsorted(os.listdir("input")): input_file = "input/" + input # 流し込み先のテンプレートを読み込む doc = docx.Document("templete.docx") with open(input_file,'r',encoding="utf-8") as f: # 1行目はタイトル,以降の偶数行目はハンドルネーム,奇数行目は本文として処理。 Flag_figure = False # キャプションのフラグ。 for n,line in enumerate(list(f),start=1): if n == 1: # 1行目のみタイトルとして処理。 title = line para = doc.add_paragraph() para.paragraph_format.widow_control = True para.paragraph_format.space_after = Pt(0) para.alignment = WD_ALIGN_PARAGRAPH.CENTER # MS Pゴシック,11 pt,中央揃えでセクションの題目を追加。 add_font_type_size_run(para,title,font["Title"],11) elif n %2 == 0: # ハンドルネームの処理。【】で囲む。 name = line.replace("\n","") font_size = 9 if name == "画像": # ハンドルネーム「画像」を検出するとキャプションとして処理する。 Flag_figure = True font_size = 7 name = "【" + name + "】" # 会話ごとにパラグラフを作成し,ぶら下がり,行間1.2倍を設定。 para = doc.add_paragraph() para.paragraph_format.widow_control = True set_hang_space_para(para,404495,1.2) # MS ゴシック,9 ptでハンドルネームをパラグラフに追加。 add_font_type_size_run(para,name,font["Name"],font_size) elif n %2 == 1: # 本文の処理。 body = line body = body.replace("\n","") # 前行で設定したパラグラフに本文を追加。日本語はMS P明朝,英数字はCentury,強調はMS Pゴシック,9 pt。 if Flag_figure: # キャプションのフラグが立っていると中央揃え,改行追加で本文を追加。 body = body + "\n" para.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER Flag_figure = False add_jpn_eng_mixed_run(para,body,font["Japanese"],font["English"],font["Emphasize"],font_size) # 仕様で冒頭のパラグラフが入るので削除する。 delete_paragraph(doc.paragraphs[0]) # inputファイルごとに変換されたdocxを出力 output_file = "output/" + os.path.splitext(input)[0] +".docx" doc.save(output_file) print(f"'{os.path.splitext(input)[0]}.docx'が'output'に保存されました。") # 統合ファイルを作る場合は各paragraphとrunを格納。 if Merge: for paragraph in doc.paragraphs: paragraph_merge = doc_merge.add_paragraph() # paragraphオブジェクトの様式を強引にコピーする。 Form, Form_merge = paragraph.paragraph_format, paragraph_merge.paragraph_format Form_merge.alignment = Form.alignment Form_merge.first_line_indent = Form.first_line_indent Form_merge.left_indent = Form.left_indent Form_merge.space_after = Form.space_after Form_merge.line_spacing = Form.line_spacing Form_merge.alignment = Form.alignment for run in paragraph.runs: # runオブジェクトの様式を強引にコピーしながら本文を入力。 run_merge = paragraph_merge.add_run(run.text) run_merge.font.size = run.font.size run_merge.font.name = run.font.name run_merge._element.rPr.rFonts.set(qn('w:eastAsia'), run_merge.font.name) # セクションごとに改行がいるので挿入。 doc_merge.add_paragraph().paragraph_format.space_after = Pt(0) # 統合ファイルを出力。 if Merge: # 仕様で冒頭のパラグラフが入るので削除する。 delete_paragraph(doc_merge.paragraphs[0]) doc_merge.save("output/merge.docx") print("'merge.docx'が'output'に保存されました。")
コードの内容(クリックすると展開されます)
- 1-7行目:モジュールの読み込み。
- delete_paragraph:既存の.docxファイルに流し込みをすると仕様で文頭に空のパラグラフが残ってしまうので,それを削除する関数。Stack Overflowのコピペ。
- add_font_type_size_run:パラグラフの最初に文章を追加するのに使う。python-docxで日本語フォントを扱うには呪文を唱える必要があるようで,qiitaを参考に実装した。
- set_hang_space_para:パラグラフの字下げや行間を設定する。特に漫トロのフォーマットのような「ぶら下がり」を設定するには「文頭だけ左側に(マイナス方向)xずらした後に全体を右側に(プラス方向)xずらす」としたらなんかできた。
- add_jpn_eng_mixed_run:フォントを制御しながら本文をパラグラフに追加する。
- 全角「!」「?」を検出するとフラグが立ち,その状態で次の文字が半角スペースじゃなかったら自動で挿入する。
- 半角「!」「?」はそれらが2個続いたことを検出する必要があるのでフラグを2つ用意し,2つのフラグが立った状態に対して同様の処理をする。全角「!?」とか全角スペースはもはや考慮していない。
- アスタリスクで囲まれた強調部分は,アスタリスクを検出する度にフラグを入れ替えることで,強調部分だけフラグを立つように実装した。アスタリスクを検出するとcontinueするのがオシャレポイント。
- unicodedata関数で日本語か英数字かを判別してフォントを決める3。以前は正規表現で判別していて気が狂いそうだった。ただし強調フラグが立っている間は強調フォントで設定を上書きされる。
- main(特に言いたいことだけ):
- font:フォントの設定をまとめた。なんとなく辞書オブジェクトにした。
- for input in natusorted(os.istdir("input")):GoogleColabで実行したら繰り返しが辞書順にならなかったのでnatsordedを入れた。
- for n,line in enumrate(list(f),start=1):別に必要ないけど分かりやすくするためにone-basedにした。
- if n == 1:こいつだけ中央揃え。para.paragraph_format.widow_control = Trueでパラグラフがページを跨がないようにする。para.paragraph_format.space_after = Pt(0)でパラグラフの初めに字下げしないようにする。詳しいことは公式ドキュメントに書いてある。
- elif n %2 == 0:画像フラグはここで立てる。ハンドルネームの略称が【画像】の会員が現れると全てが破綻する。ぶら下げの単位はよく分からないが元のフォーマットは404495らしい。なんかgetterで調べたはずなんだけどもう覚えてない。
- name = name.replace("\n",""):list(f)の中身は改行文字が含まれるので空文字で置換する。
- elif n %2 == 1:画像フラグが立っている場合はキャプションとして処理するため,改行を戻してポイントを下げて中央ぞろえにする。しかし実物なしでキャプション書けるか? という話もある。
- if Merge:デフォルトでは統合ファイルは作らないが,main()の引数にTrueを渡すと統合ファイルも作成する。力技で設定をコピーしているため上手くいかないこともある。
フォントの種類やサイズ,字下げの諸設定を変えずにやると漫トロの座談会原稿になります。使ってない設定もあるので公式ドキュメントでも見ながら好きにいじってください。
入出力ファイルの用意。
入力ファイルは.txtで以下のように行ごとに分けて記述します。余計な改行を入れると全てが崩壊します。また,強調したい部分はアスタリスクで囲っておきます。
- 1行目:セクションのタイトル
- 2, 4, 6, 8, ……行目:ハンドルネーム略称
- 3, 5, 7, 9, ……行目:上のハンドルネームの人の発言
例:6.txtの冒頭
6位『にゅるトロばいたると天国』 パイ ば! い? た!! る!?と??見!て? る!か?……!? はい なにがいいんですか? 読んでないんですけど。 倍足 *これ*readして作って*ない**ranking*は*未完成*です*よ*。 画像 ばいたるとが絶頂しているコマを挿入。生きすぎ1919
1人目の【ぱい】は全角「!」や半角「!?」が入り乱れていますが半角スペースがあったりなかったりします,気が狂う。2人目の【はい】はまともに見えますね。3人目の【倍足】は文中に日本語と英語が入り乱れているほか,強調もわけ分からんことになっています。8, 9行目には画像の指示と仮のキャプションが入力されてあります。
入力ファイルは数字で1.txt, 2.txt, 3.txt,……としておくのがベターかと思います。統合ファイルを作る場合はこの順で流し込まれますので。Googleドライブのinputフォルダに入れておいて下さい。
出力ファイルの設定については,python-docx側で無から作ることもできるらしいのですが,面倒なので普段使っているフォーマットの文章を空にしたものをtemplete.docxとして用意してやります。余白や段組みの設定などは元のファイル側から制御します。その際,本当に空のファイルにしていると設定が巧く反映されないようなので,どうせ後から消すので適当に文章を入れておきます。ここに関しては普段使っているフォーマットがあるから大丈夫でしょう。流石にWord分からないは話にならない。templete.docxはスクリプトと同じファイルに置いておいてください。

ちなみにスクリプトに流し込む前に校正は2,3回通って最低限の体裁合わせと内容のチェックは済んでいるイメージ。最近はOneDriveもブラウザ上での.txtファイルの編集に対応しているので校正の反映もオンラインでできます。校正用原稿はNotepad++でpdfにしたものを印刷するのが良いかと,行数と特殊文字が見れるので。印刷したら余白がたくさん出てもったいかもしんないけどね……。

表示→画面端で折り返す。
印刷→Microsoft Print to PDF。
これを見ると,問題なさそうだった【はい】は文末に全角スペース(IDSP)が残ってたんだと分かりますね。こういうのは校正の段階で消してから流し込みしましょう。
実行と結果
実行するにはGoogleColabで新たなコードセルを追加して,以下のコードを入力して実行するだけです。
main(True)
引数に何も渡さないで実行すると統合ファイルを作らないで個別のファイルだけ流し込みします。原稿がそろってない場合はするといいかも。
実行すると'1.docx'が'output'に保存されました。などと表示されます。出力フォルダは自動で作成されるので問題ありあません。出力される.docxファイルは元の.txtファイルと同じファイル名になっています。
<追記> Google colabで実行したファイルの保存がGoogleドライブに反映されるまでには,それなりにタイムラグがありそう。気になるならローカル環境で実行した方がいいかも。 <追記終わり>
出力されたファイルを見てみるとこんな感じ。見やすくするために半角スペースと全角スペースを可視化しています。

ファイルを確認したところ,
- ハンドルネームと本文の日本語,英数字,強調でフォントが分かれている。
- ハンドルネームのところで適切に字下げされている。
- 全角「!」や半角「!?」などには適切に半角スペースが挿入されている。
- 画像とキャプションを入れるべきところのポイント数が調整されている。
などが実現されていました(豆腐は全角スペースなので元のファイルに残ってるのが悪い)。これによって座談会原稿の体裁を整える煩わしい作業から解放されると考えられます。やったね!!
終わりに
これにて座談会原稿の作業の多くを自動化することができました。漫トロ民に分かりやすく言うと「ふわぺろのコピペ作業からもう解放された」ということです,たぶん。実際どんなもんなんですかね。シチョウくんに使わせたら「作業効率が大幅に上がった」と言っていましたが,少しでも楽になったなら老害冥利に尽きます。こんだけ労力減らしてやったんだから締め切りブッチが減るといいですね。
またこんな場末のブログなんて見られないと思うが,評論島の皆さんの座談会原稿の作成に一助になれば幸いです。
なお本稿は引継ぎ文書も兼ねている。漫トロGoogleアカウントが見つからなかったので自分のでやったが,たぶん役に立つと思うので,暇なときに記事の通りに動かしてもらえると嬉しい。俺(?)もふれにあも卒業してしまうが保守はまぁ……シチョウ(と にく)がおるし大丈夫やろ。
メメ太さん聞こえますか? 俺からあなた(達)への鎮魂歌です
")